

新媒易动态
NEWS CENTER

NEWS CENTER
2020-06-11
从功能实现层面对智能对话机器人的做了五个类别区分,如果从对话机器人实际解决的问题范围来看,也可以将其分为两个大类:封闭域对话机器人和开放域对话机器人。不难从字面上就很容易理解,封闭域即为在限定的领域内完成对话,而这些领域是由设计产品的人进行人为限定的;而开放域则没有限制,一般支持的会话是广泛领域内的公共范畴。
但就目前的最终效果来看,开放域对话机器人很难做好用户体验,一旦给用户设定什么问题都可以问什么话都可以聊,那用户就一定会问出bug…实际大多数的产品设计目前都聚焦于一个或几个特定领域内(开放域仅作为分支补充功能),便于为目标用户提供更好的产品体验。
智能对话机器人的主体框架:
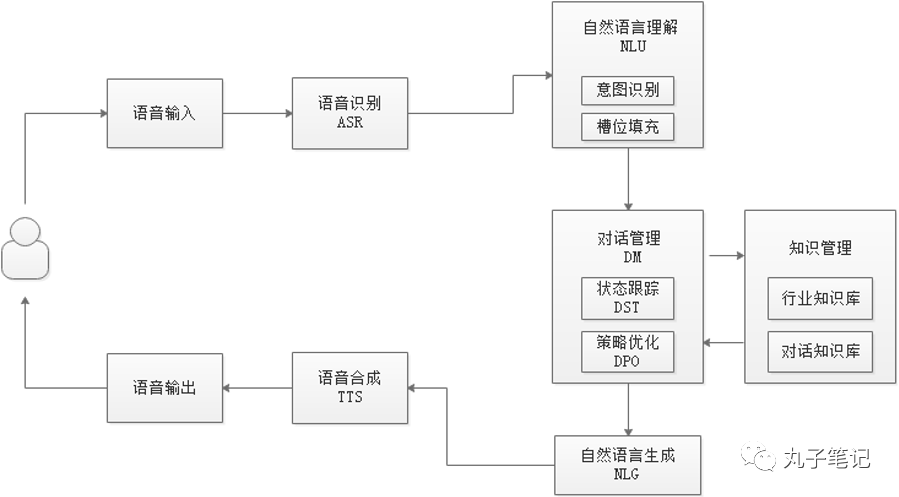
通常来说如上图所示,智能对话机器人整个框架分为7个模块,但也可根据实际设计的产品功能进行增减,增减的部分主要聚焦在输入/输出的部分,后面会进行具体解释。
对话机器人,那对话就是一个核心的交互方式,那么基于具体的产品是软件or硬件,硬件里面是有屏or无屏,其实都会在输入输出的交互方面产生细微的差异。
语音输入当然是便捷的,它突破了用手打字的部分局限,从而扩展了智能化产品的使用场景,比如开车时的语音地图导航,比如临睡前的语音关灯等等。
另一方面,我们必须意识到,语音输入自身存在的局限性:
而语音输出的局限性也显而易见,一旦机器人的回答话术比较长,那么对于用户来说等待机器人输出完整的语音所花费的时间绝对比通过视觉获取同等信息高出很多倍,所谓“一目十行”即是这个道理。毕竟人类已经掌握了通过视觉快速从大量文字图片信息中获取关键信息的技巧。
因此,如果你的产品有让用户可以进行操作的屏幕,那么在输入/输出端,最好支持多模态,比如语音、文字、以及触觉(通过屏幕点击、完成部分对话场景的信息交互)等适应用户复杂的使用场景,提升用户使用效率。
当然,在信息输出的部分,目前也有多款纯软件类产品仅支持文字图片等结果输出,不支持语音输出,究其原因大概有以下3个方面:
综上:在输入输出方面,可依据自己的产品场景进行合适的选择。
一般的智能对话机器人产品目前直接使用主流厂商提供的功能即可,包括:讯飞、百度、腾讯等。业内总体语音识别准确率在量级上相差不是很大,一般分免费和付费两种,用户体量小一般免费即可够用,稍大点的产品需要对比各家不同的资费进行选择即可。
在语音识别方面目前可能存在的问题是:大厂的语音识别语料基于更广泛的场景,而一旦你的产品属于垂直领域,即有一些特殊行业的词汇时,就会出现通用识别能力识别不准的情况,从而造成整个流程识别错误最终反馈给用户错误的结果。
当然,大厂也是可以做定制的,目前也支持用户进行词库的导入,从而在一定程度上解决这个问题。同时,多数厂商也有语音识别纠错的功能,总体体验都还可以。此处不再赘述,相关信息可自行查询。
这个模块即为机器人理解用户输入信息的核心模块,即让机器人“理解”用户。主要分为2个部分:意图识别(intent)和槽位填充(slot filling)。
意图识别需要由产品所需要支持的功能进行圈定,可以识别单个意图也可以识别多个。比如,你是一个单纯的查天气的机器人,那么你的意图识别领域就是需要界定出用户输入的信息是否是“查天气”,又比如你是一个出行领域的机器人,那么你的意图识别就需要确定是“订机票”还是“订火车票”“订汽车票”等等。
意图识别目前涉及到的技术主要分两大类:基于规则、基于算法。而意图识别的难点就在于每一种意图都有多种多样的表达,比如用户要“订机票”,可能存在的表达如下:
仅仅基于规则很难准确识别用户的多种表达方式,所以目前主流做法是【少量规则+算法模型】,而比较主流的算法模型包括:CNN、LSTM等。
槽位填充即是想要达成目标意图所需要的必备或者识别等关键内容。比如意图识别为“查天气”那么所需要填充的槽位就是“地点”,机器人需要回答天气,必须是指定城市或区县的天气,这个“地点”即为必填的【槽位】。而如果是“订机票”的场景,那么需要的槽位就包括“出发地”“到达地”“出行日期”,而用户如果说了机票业务场景内的“公务舱”则可以作为非必填但需要识别的实体信息。
一般多轮对话机器人均需要做对话管理,因为对话是持续进行的,所以每次机器人进行答复时需要针对当前的会话状态给出合适的回复。对话管理分为两个模块:状态跟踪(DST)、策略优化(DPO)。
状态跟踪就是表示:t+1 时刻的对话状态,依赖于之前时刻 t 的状态,和之前时刻 t 的系统行为,以及当前时刻 t+1 对应的用户行为。因此确认当前意图和槽位信息是状态跟踪的核心,需要明确当下的对话状态进展到哪一步。
策略优化则是根据状态跟踪的结果给出机器人应该在当前对话状态下需要给出的正确回复。
举例来说在“订机票”这个对话过程中,需要根据用户当前不同的对话状态节点给出不同的回复,如下两种状态:
场景一: